

A cache is a memory based database made for quick retrieval of data in case of any failure. A distributed cache runs as an independent processes over various hubs and offer a single logical view (and state) of the cache. Distributed Cache can be used to distribute simple, read-only data/text files and application workloads that do more reading than writing of data. To make it more clear in simple words if you have data 1, data 2, data 3 and server A, B and C. Then for data 1 you need to store it in server A, and the back it up in B and C. Again for data 2 you need to store it in server B, and back it up on server C and so on. In case there is a failure in main server the data is retrieved from the back up server. Hashing algorithm is generally used to determine on which node a particular key-value resides. While job execution the cache files should not be copied or executed. The performance variables for distributed caches depend on factors like .
- Network Bandwidth.
- Object Size.
- Object Count.
- Clients to Node Ratio.
- Serialization.
- Read Write Pattern.
Architecture of Distributed Caches
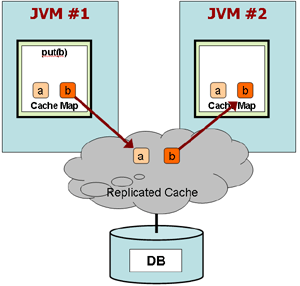
EXAMPLE:
- Memcached: Commonly known as memory cache. It is famous for it high-performance, highly scalable key-based and open source system.
- Redis: Near similar to Memcached, its just a data structure server .It can be used as a real database instead of a volatile cache.
- Ehcache: The best used JAVA platformed cache. Minimal dependency only on Simple Logging Facade for Java (SLF4J), light weight and fast.